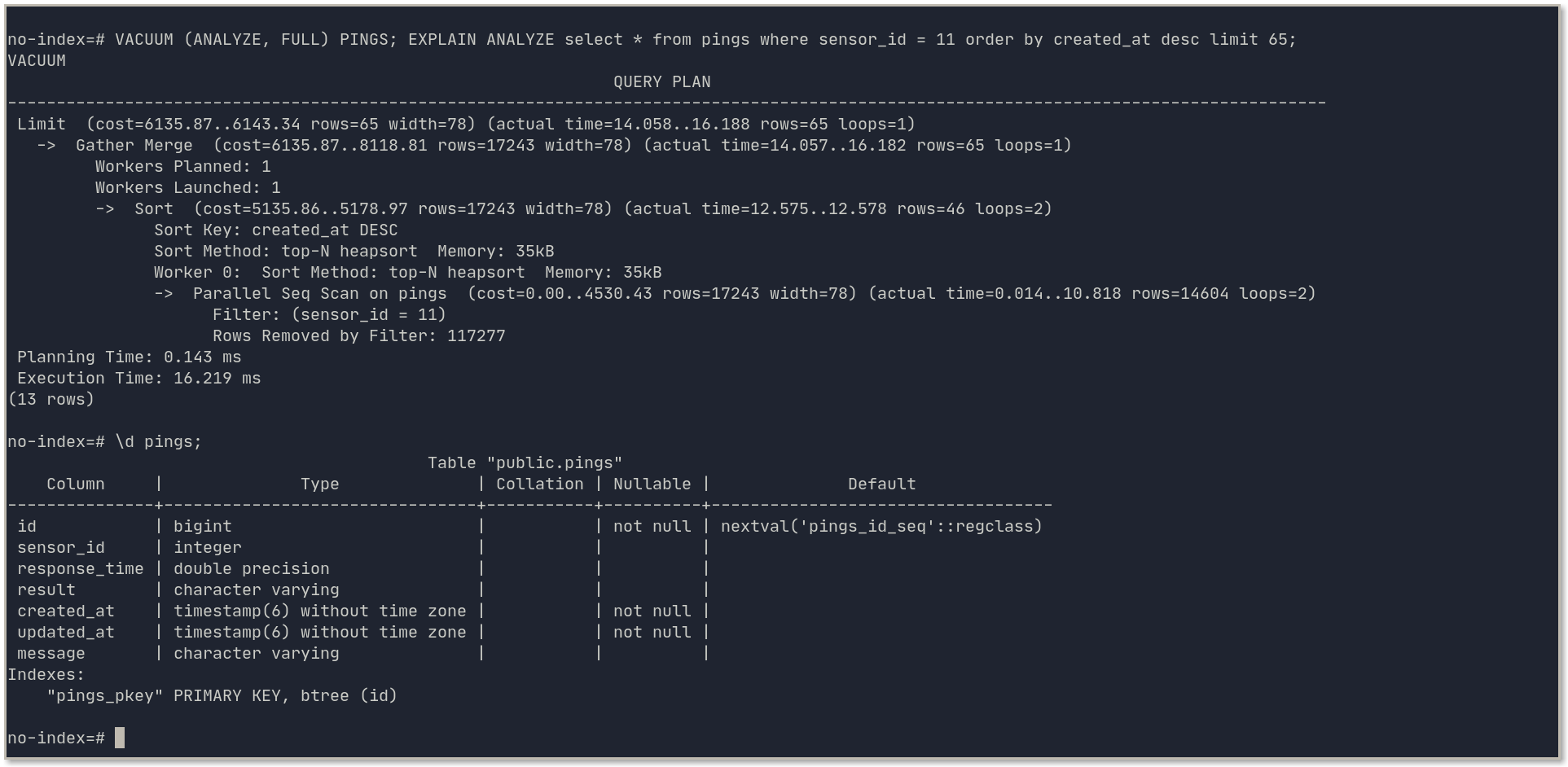
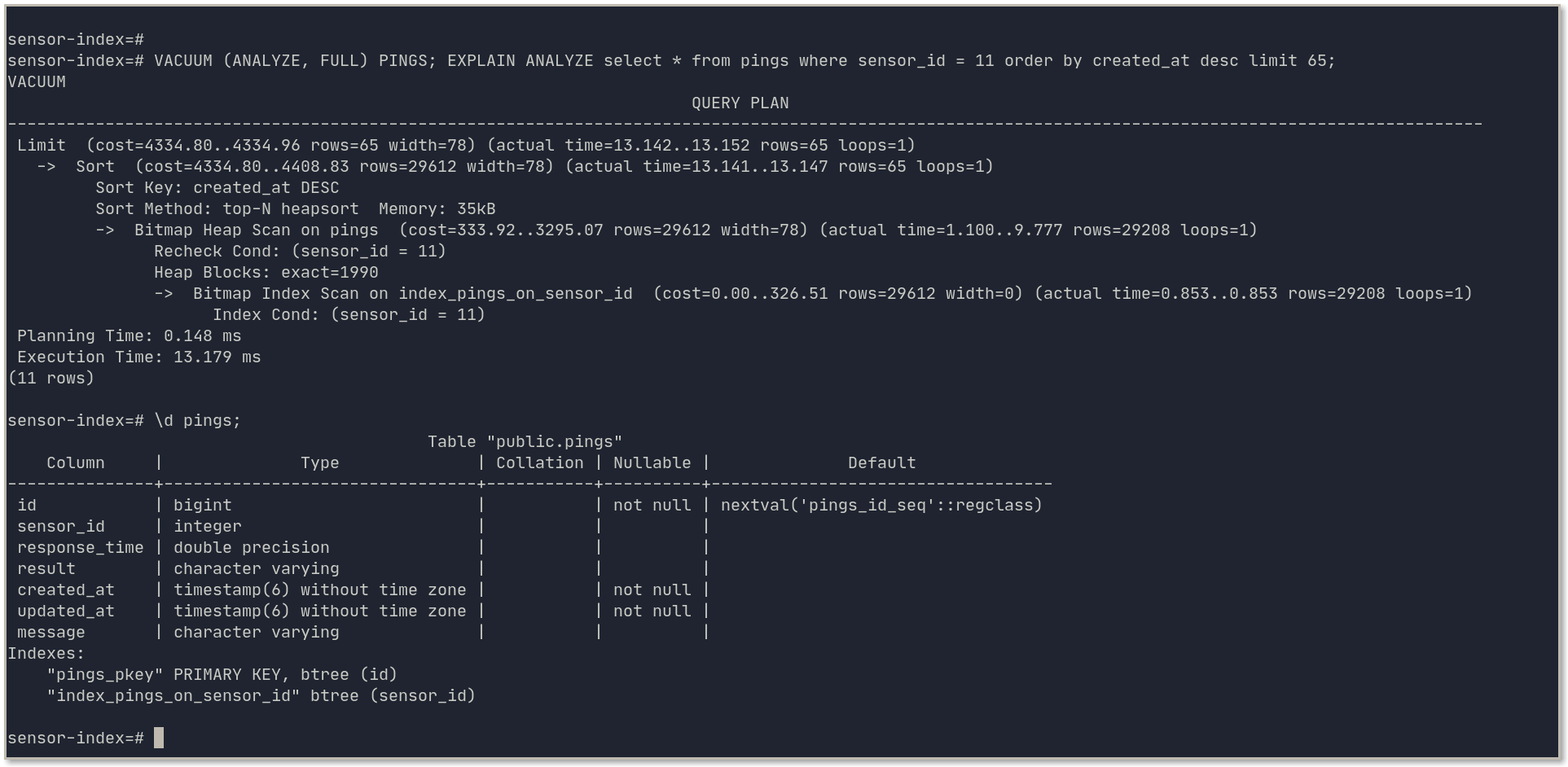
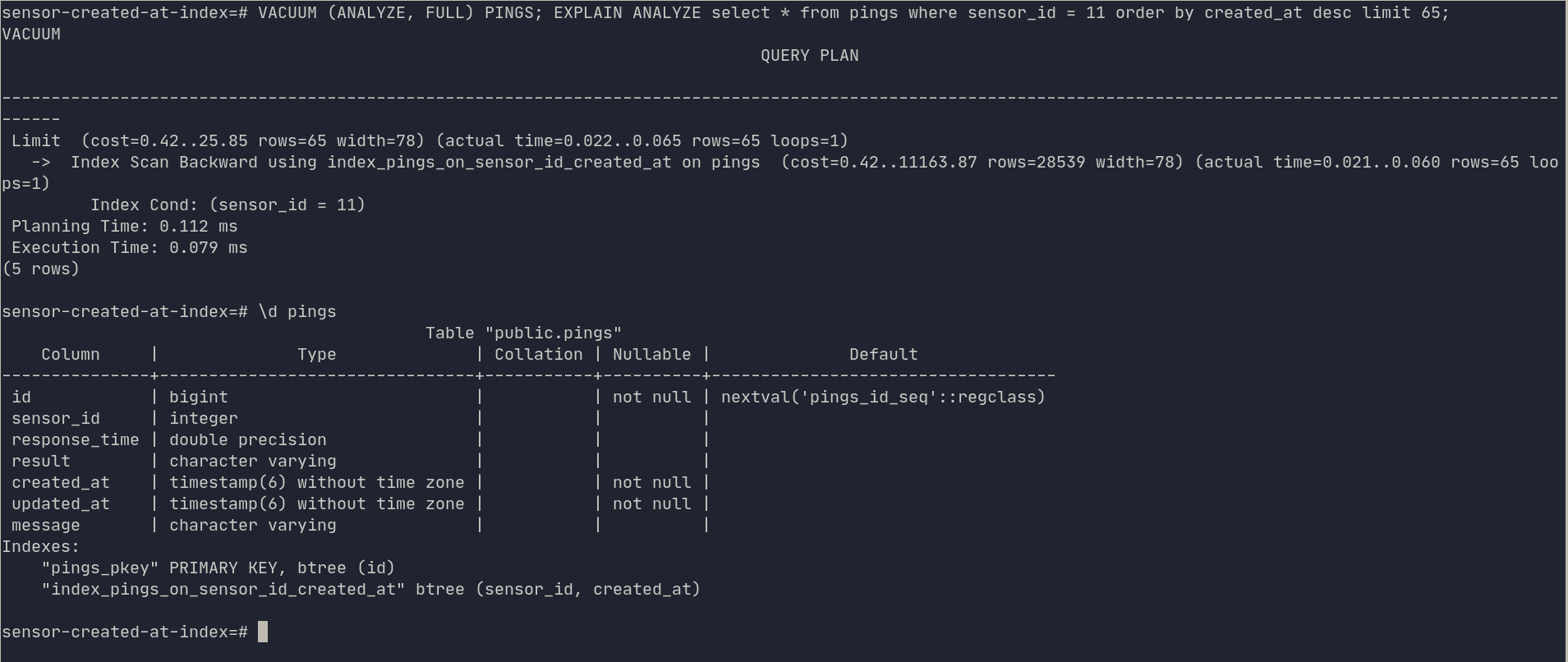
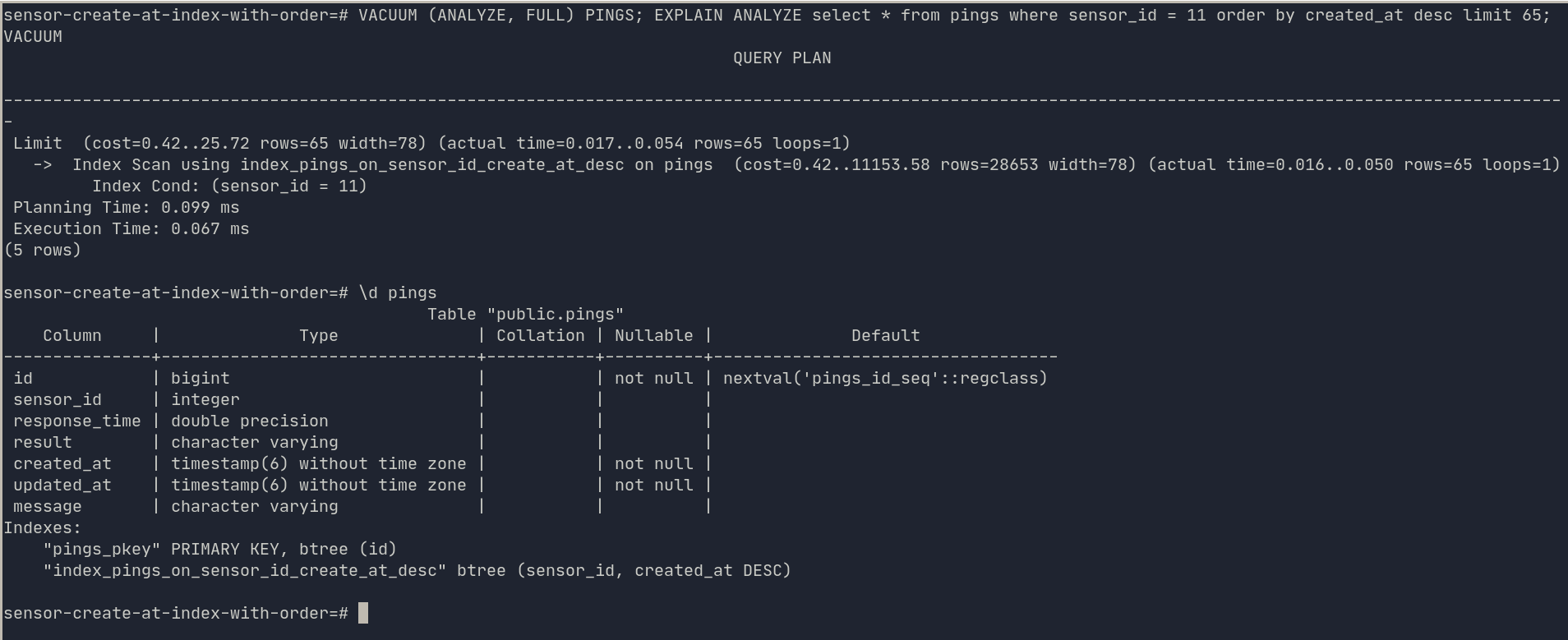
Did you know that AWS RDS for PostgreSQL uses the default PostgreSQL configurations with minimal customization? There’s a good chance you can get more out of your database. Lets examine the parameters parameters that can dramatically improve a PostgreSQL database’s performance.
work_mem
This parameter determines the amount of memory allocated for sorting operations during queries. Insufficient work_mem can cause operations to spill onto disk, slowing down the qeurying process, while excessively high settings may deplete memory available for new connections. The optimal way to adjust work_mem is by monitoring your system. Start with 4MB for most new apps; if you’re running client reports, like a monthly summary, consider bumping it to 8MB.
log_temp_files
Enabling this setting helps track queries that are spilling to disk, indicated by log messages about temporary files or “external merge Disk”. For web applications with administrative backend or reporting functionality, starting with 4MB is advisable, adjusting as needed based on workload demands. Values larger than 64MB suggest conflicting workload requirements. Consider using a read replica for queries that require more memory.
maintenance_work_mem
By allocating more memory to maintenance_work_mem, maintenance tasks complete more rapidly, which minimizes the downtime or slow performance associated with these operations. This will increase the overall throughput of your database by helping it spend less time locked in maintenance tasks and more time serving requests. A good starting point is setting maintenance_work_mem to around 50% of your total memory.
Checkpoint Parameters
- checkpoint_completion_target
- checkpoint_timeout
- max_wal_size
- min_wal_size
- log_checkpoints
The default settings in PostgreSQL lead to excessive checkpointing, creating additional write loads. The aim is to have regular checkpoints, guided by the checkpoint_timeout parameter. Increase max_wal_size gradually if the system hits the limit often, and increase checkpoint_timeout for databases with high I/O during checkpoints. For checkpoint_timeout, values up to one hour are sensible.
Here is a good “starter” configuration for a host with 4GB of memory:
checkpoint_completion_target = 0.97
checkpoint_timeout = 25m
max_wal_size = 4GB
min_wal_size = 512MB
log_checkpoints = on
wal_buffers
wal_buffers are important for improving write performance on servers where many clients are committing transactions simultaneously. The previous default of 16MB is a solid start– I recommend increasing this by 4MB for each CPU core (minus one). Please note, a system restart is required to apply the new settings. To minimize downtime, consider adjusting wal_buffers together with max_connections.
max_connections
Increase the default to 200 to allow for more simultaneous connections. This requires a restart, but restarting now affects fewer customers, making it a preferable option. Consider using AWS RDS Proxy for higher demands or if restarting isn’t an option.
effective_io_concurrency
This setting controls how many concurrent operations the underlying system can handle. Adjusting this parameter can lead to significant performance improvements for databases frequently performing Bitmap Heap Scans. I recommend starting with a value of 25 times the number of CPUs– you can explore settings up to 1000.
Logging Parameters
- log_statement
- log_min_duration_statement
- log_lock_waits
To prevent the potential exposure of Personally Identifiable Information (PII), set log_statement to none to disable it and change the slow_query_logging setting to -1 to turn slow query logging off. To identify slow queries, consider using the auto_explain extension for brief periods. Enable log_lock_waits to identify whether extended lock waits occur. Lock wait timeouts lead to lower throughput.
statement_timeout
Long queries consume resources, slow down queries, block new connections, and cause conflicts with other transactions. Setting the statement_timeout parameter to a maximum of 80% of the client timeout is recommended to prevent this scenario. For instance, if using Puma with a default timeout of 60 seconds, set the statement_timeout parameter to a maximum of 48 seconds.
By adjusting these fifteen PostgreSQL parameters, you can significantly boost your database’s performance.
For those running PostgreSQL on AWS RDS or similar environments, remember that while defaults get you started, they are rarely optimized for all workloads. The configurations suggested here, including the starter settings for a 4GB server, are just the beginning. Customize them further based on your system’s specific demands and usage patterns.
Continual monitoring and adjustment of these parameters as your database grows and evolves are essential to maintaining a robust, responsive system. Keep experimenting, keep optimizing, and you’ll see not just improved performance but also potentially lower costs and happier users.
Notes
Photo by Adi Goldstein on Unsplash
]]>